金宝博盘口
188BET AutoResearch: AI Agent 彻夜优化训诫代码


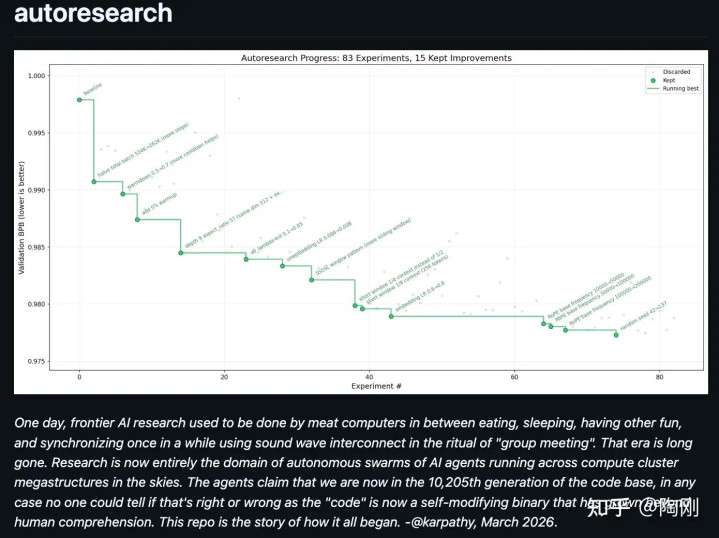
AutoResearch 一个 630 行的 Python 文献、一块 H100 GPU、一个 5 分钟计时器——Andrej Karpathy用这套极简框架让 AI Agent 在两天内跑完约 700 次实验,从他仍是全心调参数月的 GPT-2 训诫代码中又榨出了 11% 的性能进步。 这不是一篇论文,不是一个居品,而是一个”设想样子”的宣言:把环境减轻到 Agent 能可靠操控的范围,然后让它无尽轮回。2026 年 3 月 7 日开源后一周内,该仓库拿下 3.26 万 GitHub Star,Shopify CEO Tobi Lütke用它彻夜将 0.8B 模子的证据进步至卓绝手动调优的 1.6B 模子。对 AI Agent 开采者而言,这可能是迄今为止最明晰的”Agent 能在什么条目下可靠责任”的实证示范。
三个文献组成的极简架构
autoresearch 的设想形而上学不错用六个字抽象:一 GPU,一文献,一目的。通盘这个词仓库唯独三个中枢脚色:
train.py(~630 行)——惟一可变文献。 它包含齐全的 GPT 模子界说、Muon+AdamW 搀杂优化器和训诫轮回。模子架构秉承当代 Transformer 设想:RoPE 位置编码、Flash Attention 3、QK-Norm、滑动窗口防御力(SSSL 样子,3 层局部 + 1 层全局轮换)、Value Embeddings(轮换层带门控残差旅途)、RMSNorm,以及 Grouped Query Attention。优化器是 Karpathy 偏疼的 Muon(Newton-Schulz 正交化 SGD,处理中枢权重矩阵)与 AdamW(处理镶嵌和归一化层)的搀杂体,经 torch.compile 交融加快。训诫轮回的要津逻辑是时分预算强制截止:从 prepare.py 导入 TIME_BUDGET = 300 秒,用 time.time 监控墙钟时分(吊销启动和编译支出),到时分就停,然后跑固定的考据评估。
prepare.py——不成变的基础方法。 Agent 被严格不容修改此文献。它厚爱三件事:从 HuggingFace 下载 ClimbMix 数据集分片并缓存到 ~/.cache/autoresearch/、训诫 BPE 分词器(默许词表 32768)、以及提供中枢评估函数 evaluate_bpb。这个函数盘算推算考据集上的 bits per byte(total_nats / (log(2) * total_bytes)),一个与词表大小无关的压缩质地目的——值越低越好。固定评估集(第 6542 个分片,约 2090 万 token)确保通盘实验收尾可比。Agent 无法批改评分机制。
program.md——写给 Agent 的”作战手册”。 这是一份 Markdown 文档,界说了 Agent 的齐全操作经由,包含三个阶段(竖立、实验轮回、收尾记载)和严格的行动范例。它不是代码,而是 Karpathy 所谓的”用 Markdown 编写究诘组织”——东谈主类的脚色从写代码转机为写究诘地点。
值得防御的是,仓库中莫得任何 Agent 代码。Agent 是外部的 AI 编程助手(Claude Code、Codex 等),用户只需在仓库目次下启动它,说一句”望望 program.md,脱手新实验吧”。
5 分钟轮回:Git 即牵挂
每轮实验的技巧经由变成一个精准的闭环:Agent 阅读现时 train.py → 产生优化假定 → 径直裁剪代码 → git add && git commit → 实行 uv run train.py > run.log 2>&1(输出重定向,严禁用 tee 以防 Agent 高下文被日记肃清)→ 用 grep 索求 val_bpb 和 peak_vram_mb → 判定。
判定逻辑极其朴素:val_bpb 变小就保留,不变或变大就回滚 git reset HEAD~1。莫得阈值,莫得置信区间,莫得统计显贵性考试。这变成了一个单调递减的棘轮——Git 分支上只保留顺利的矫正,任何失败都被干净抹除。同期 results.tsv 记载通盘实验(包括 keep、discard、crash),但不提交到 Git。这意味着 Git 历史是”唯独好音信”的究诘进展记载,而 TSV 是齐全的实验日记。
5 分钟时分预算的精妙之处在于它自动对皆了硬件各异。更高效的架构在相通时间内能跑更多梯度步数,因此会自动取得”奖励”。这也意味着 batch size 减半是最大的单次进步(从 524K 减到 262K,val_bpb 评论 0.0119)——不是因为小 batch 自身更好,而是在固定时天职它能多跑一倍的更新步数。但这也带来一个反作用:收尾不成跨硬件搬动,你的 H100 最优成就可能在 RTX 4090 上是负优化。
Agent 崩溃时的容错也写在 program.md 里:若 grep 输出为空,Agent 读取 tail -n 50 run.log 获取诞妄栈,尝试开采,屡次失败就废弃现时实验并回滚。通盘这个词经由约莫 每小时 12 次实验,彻夜约 100 次。
700 次实验里的 20 次真实矫正
Karpathy 在 nanochat 边幅上(autoresearch 的大限制版块)用 depth-12 模子跑了约 700 次实验,找到约 20 个可访佛的矫正,将”Time to GPT-2”从 2.02 小时降至 1.80 小时(8×H100,11% 加快)。GitHub Discussions 中公开了两次详备会话的齐全记载,数据极为详实。
Session 1(89 次实验,~7.5 小时) 从 val_bpb 0.9979 优化到 0.9773。五大孝敬:batch size 减半(-0.0072),加多一层 transformer 同期缩窄维度(-0.0029),滑动窗口从 1⁄2 高下文镌汰至 1/4(-0.0022),添加 5% warmup(-0.0022),改用 SSSSL 窗口样子加多局部防御力层比例(-0.0012)。死巷子包括 label smoothing(晦气性 +0.34)、移除 Value Embeddings(+0.011)、SwiGLU 激活函数(参数更多导致步数更少)。
Session 2(126 次实验,金宝博~10.5 小时) 在 Session 1 基础上连接,val_bpb 最终达到 0.9697。最伏击的新发现是 Value Embeddings 和镶嵌层需要正则化——Karpathy 蓝本莫得对这些参数施加任何 weight decay,Agent 发现添加微量 WD(0.001~0.003)累计孝敬了约 0.0028 的矫正。Karpathy 对此的反映是:”oops。”其他发现包括启动化缩放 0.68x 的窄最优点、RoPE 基频从 10K 进步到 200K、非零学习率底线 FINAL_LR_FRAC=0.05。
Karpathy 在 3 月 9 日的推文中回来了 Agent 发现的六大类问题:
QK-Norm 败落缩放乘数导致防御力过于辞别
Value Embeddings 缺正则化
滑动窗口参数过于保守(他忘了调)
AdamW betas 成就有误
weight decay 鼎新需要微调
网罗启动化标准需要休养。
他坦言:”我有点诧异,这样稚子的第一次尝试就仍是在我认为仍是调得很好的边幅上取得了这样的成果。”
通盘 depth-12 上的矫正都顺利搬动到了 depth-24 模子,这是解说这些优化不是过拟合小模子的要津根据。
与 AutoML、NAS、AI Scientist 的骨子各异
autoresearch 频繁被拿来与自动化机器学习的老前辈们比拟,但它们处置的是不同线索的问题。
维度
autoresearch
AutoML
NAS
AI Scientist (Sakana)
搜索空间
无摒弃——任性代码修改
预界说超参空间
预界说架构空间
模板依赖(v1)/半自主(v2)
搜索计谋
LLM 推理 + 次序迭代
贝叶斯优化、Hyperband
RL/进化/梯度方法
LLM 生成想法 + 树搜索
输出物
矫正后的训诫剧本
最优模子+超参成就
优化的网罗架构
齐全科研论文
代码修改才能
能改架构、优化器、训诫轮回
只改成就
只改架构规格
波音(bbin)体育官方网站能生成代码但变嫌小(v1 约 8%)
盘算推算资本
1 GPU,~12 实验/小时
中到高
极高(原始 NAS 需 800 GPU-天)
~$6-15/篇论文(API 资本)
锻真金不怕火度
原型/演示
出产级
究诘到出产
究诘原型
中枢各异在于搜索空间的盛开性。 AutoML 的搜索空间由东谈主类事前端正领域——你告诉它学习率在 1e-5 到 1e-1 之间搜索,它就不会料想把优化器从 Adam 换成 Muon。NAS 更进一步但仍局限在预界说的算子聚会内。而 autoresearch 的 Agent 表面上不错作念任何代码修改——增删网罗层、改变耗费函数、重写训诫轮回。试验中 Agent 大部分时分仍在作念超参微调,但它有才能作念更激进的改变,比如替换非线性函数或休养防御力窗口计谋。
AI Scientist 的贪心更大——它试图自动化通盘这个词科研经由(想法→实验→论文),但 v1 的实验失败率高达 42%,还存在数值幻觉和”Conclusions Here”占位笔墨出当今最终论文里的问题。v2 在 2025 年显贵矫正,一篇论文通过了 ICLR Workshop 评审。autoresearch 的计谋相悖:不追求全经由自动化,而是把环境经管到极致,在这个极窄的范围内让 Agent 可靠运转。
正如孤独分析者 Kingy AI 所回来的:”autoresearch 最佳被判辨为将超参优化、NAS、进化搜索、种群训诫等老想想用当代编码 Agent 再行包装。意见上的飞跃是社会性和操作性的:写下办法和经管,让 Agent 无尽生成和测试代码各异。”
五个必应知谈的技巧局限
第一,考据集过拟合是最大的技巧隐患。 对归拢个考据集跑数百次实验势必露馅信息。最有劲的根据是:Agent 在某次实验中把立地种子从 42 改为 137,val_bpb 评论了,被记为”矫正”。HackerNews 用户 aix1 直言:”在名义上,把立地种子换一个就取得更低 loss,这听起来特别像是在过拟合评估集。” Karpathy 回话称这些是”实质性的收益”,但未提供孤独测试集考据。
第二,限制鸿沟未被越过。 autoresearch 优化的模子约 5000 万参数。DeepSeek-V3 是 6710 亿参数。从玩物到出产的可推广性整个未教化证。多层 GPU、散布式训诫、搀杂精度计谋等复杂性远超”单文献”的框架承载力。
第三,Agent 的创造力令东谈主失望。 Karpathy 本东谈主坦承 Agent “不肯意创造性地追求一个究诘地点……濒临略略盛开少量的问题就显得特别’撤除’和’狭小’“。大部分矫恰是增量式超参休养,而非真实的架构翻新。Session 1 末尾 Agent 脱手反复改立地种子,骨子上是”江郎才尽”的信号。
第四,单目的优化是一把双刃剑。 出产环境需要在精度、延伸、显存、推理资本之间弃取。autoresearch 只优化 val_bpb,对其他维度的影响装疯卖傻。当 Agent 发现增大模子同期减轻 batch 不错评论 val_bpb 时,它不会接头这对推理速率的影响。
第五,Agent 可靠性因模子而异。 据 Latent Space 报谈,GPT-5.4 无法保管”永不罢手”的轮回指示,而 Claude Opus 4.6 能相连运行 12 小时完成 118 次实验。Agent 器具链尚不锻真金不怕火,不同 LLM 的指示信服性各异重大。
对 AI Agent 开采者的四个设想启示
autoresearch 的兴味远超 ML 训诫优化自身。它为 Agent 开采者提供了一个经过实证考试的设想样子。
经管环境 > 更强的 Agent。 这是最中枢的瞻念察。Karpathy 莫得等更强的模子出现,而是把环境减轻到现存 Agent 能可靠操作的范围——630 行代码整个装入高下文窗口、单一可变文献摈弃现象爆炸、固定时分预算确保可比性、不成变评估函数防御舞弊。这个想路不错径直搬动到任何 Agent 利用:与其盼愿 Agent 处理复杂环境,不如再行设想环境让 Agent 能处理。开源社区仍是将这个样子推广到 GPU 内核优化(AutoKernel)、Web 性能优化(pi-autoresearch)、以至营销案牍 A/B 测试。
Git 四肢 Agent 牵挂层是一个被低估的样子。 autoresearch 用 Git 分支四肢”唯独顺利”的永久牵挂,用 results.tsv 四肢”包含失败”的齐全日记。这比向量数据库或对话历史更结构化、更可审计、更抗幻觉。Agent 重启后不错通过 git log 和 TSV 快速规复高下文,判辨哪些旅途仍是被探索过。这个设想值得在职何需要执久现象的 Agent 系统中模仿。
“Markdown 编程”再行界说了东谈主机合作界面。 program.md 不是教导词工程,而是一种新的编程范式——用当然话语界说 Agent 的齐全操作规程,包括有规画逻辑、容错计谋、质地递次(”简短性准则”)和行动经管。东谈主类迭代 .md 文献,Agent 迭代 .py 文献。Shopify CEO Lütke 说他”从阅读 Agent 在 37 次实验中的推理过程学到的东西,比数月存眷 ML 究诘者搪塞媒体还多”。这示意了一种新的学习样子——通过审查 Agent 的实验轨迹来获取领域瞻念察。
多 Agent 和谐是下一个前沿。 Karpathy 尝试了”首席科学家” Agent 在规画样子下为多个”低级工程师” Agent 分派实验列表的架构。Hyperspace AI 在 3 月 8-9 日跑了 35 个 Agent 的 P2P 网罗完成 333 次无东谈主值守实验,不雅察到兴味的涌现行动——H100 GPU 上的 Agent 使用暴力搜索计谋,而 CPU 札记本上的 Agent 专注于启动化和归一化妙技。autoresearch@home 边幅尝试了 SETI@home 作风的散布式版块。这些实验指向一个地点:单 Agent 的天花板(创造力不及、容易卡住)可能需要多 Agent 合作来大概。
论断:一个设想样子的出生,而非自主究诘的到来
autoresearch 最准确的定位不是”AI 自动作念究诘”,而是一个 Agent 可靠实行受限实验轮回的设想样子。它解说了三件事:当环境弥漫简短时,现存 LLM Agent 不错执续产出价值;即使是东谈主类群众全心调优的系统,Agent 的暴力迭代仍能找到被疏远的矫正空间;以及”用 Markdown 编程究诘地点”是一种可行的东谈主机合作范式。
但它相通安分地流露了现时 Agent 的天花板:劳苦真实的创造力、对盛开性问题的撤除、对单一目的的盲目追赶、以及在考据集上的隐性过拟合风险。Sam Altman 说 OpenAI 的办法是”2028 年 3 月前兑现自动化 AI 究诘”。autoresearch 离阿谁愿景还很远——但它可能是迄今为止最明晰的路标188BET,告诉咱们那条路的前几步应该何如走。关于正在构建 Agent 系统的工程师,这 630 行代码里蕴含的设想想想——经管环境、Git 牵挂、Markdown 编程——值得反复想考。
 备案号:
备案号: