金宝博盘口
188BET AI性能暴增35倍! 英伟达发布全新LPU, GPU不再是唯独主角!

当地时辰3月16日,英伟达GTC 2026厚爱好意思国加州圣何塞召开。英伟达独创东说念主兼首席施行官黄仁勋身披标识性皮衣登场,在长达两个半小时的主题演讲中,勾画出这家算力巨头从“芯片公司”向“AI基础枢纽工场”全面转变的宏伟蓝图。
面对市集对功绩抓续性的高度护士,黄仁勋给出了极为苍劲的预期:到2027年,英伟达新一代AI芯片的累计营收将厚爱跨入1万亿好意思元时间。这一数字是他前年预测的两倍。
本次演讲的一大重心,当属备受期待的Vera Rubin AI工场平台。与以往发布单芯片不同,黄仁勋这次展示的是一个包含7款全新芯片的“全家桶”系统。他强调:“当年提到Hopper,我会举起一块芯片,那很可儿。但提到Vera Rubin,全球意象的是通盘系统。”

这一系统级平台的中枢组件包括:
Vera CPU:全球首款专为“AI智能体时间”与“强化学习”狡计的处理器。它搭载88个自研“Olympus”中枢,性能较传统CPU快50%,能效进步达2倍。黄仁勋将其比作智能体系统背后的“调换与改革中心”,负责经管海量并发任务。
Rubin GPU:与Vera CPU通过NVLink-C2C时期达成1.8TB/s的惊东说念主互联带宽,共同组成壮健的算力中枢。
NVLink 6 Switch、ConnectX-9 SuperNIC、BlueField-4 DPU以及带同包光学器件的Spectrum-X可推广交换机:组成了一套齐备的超高速互联、集结与数据处理基础,确保数据在AI工场内高效流转。
黄仁勋展示了基于这些组件构建的Vera Rubin NVL72机架,它集成了72颗Rubin GPU和36颗Vera CPU。比拟上代Blackwell平台,查考大型夹杂各人模子所需GPU数目仅为其四分之一,推理糊涂量/瓦特进步高达10倍。他猖獗地宣称,通过极致的软硬件协同狡计,在短短两年内,英伟达将1GW数据中心内的Token生成速率进步了350倍。
稀奇值得重心先容的是,黄仁勋展示Vera Rubin平台的“全家桶”时,还推出了一款看似工整却极具战术意想的芯片——Groq 3言语处理单位(LPU)。这款源自英伟达前年12月以约200亿好意思元收购Groq中枢时期钞票的芯片,被黄仁勋定位为Rubin GPU的“推理协处理器”,成为了Vera Rubin平台的又一基石。
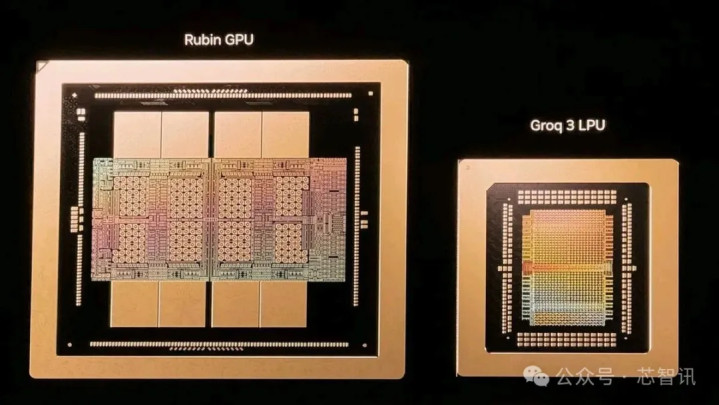
黄仁勋讲授了引入LPU的战术考量时指出:在AI智能体时间,推理需求正加速分化。面对需要极高交互性、超短反映时辰的任务,传统GPU架构存在性能冗余。为此,英伟达引入了专注于“极致低延长Token生成”的LPU架构。
本文将深入领会Groq 3 LPU的时期细节、夹杂推理架构以及它对AI推理市集的深切影响。
一、时期颠覆:打造150TB/s的SRAM怪兽
Groq 3 LPU最引东说念主注指标特质,在于其透澈颠覆了传统AI加速器的内存架构。
1、500MB片上SRAM:带宽的极致追求
与大多数依赖HBM(高带宽内存)行为责任内存层的AI加速器不同,每个Groq 3 LPU芯片集成了500MB的片上SRAM(静态马上存取存储器)。这种内存此前主要用于CPU和GPU的超高速缓存,从未在AI加速器中担当主角。
这500MB SRAM看似“微不及说念”——与每个Rubin GPU上容量高达288GB的HBM4比拟,仅为其1/500。但SRAM的环节上风在于带宽:这块SRAM可提供高达150TB/s的带宽,而HBM4的带宽仅为22TB/s。这意味着,关于带宽相配明锐的AI解码操作,Groq 3 LPU的带宽是传统HBM的近7倍。
波音(bbin)体育官方网站
英伟达超大范畴估计副总裁Ian Buck对此讲授说念:“让咱们对比一下这两种处理器:GPU领有288GB内存,但带宽是22TB/s;LPU唯独1/500的容量,但带宽达到了惊东说念主的150TB/s。关于需要极致低延长的token生成任务,ag真人appLPU的带宽上风无可替代。”
基于此芯片的Groq 3 LPX机架配备256颗LPU,提供128GB片上SRAM和640TB/s总带宽。

黄仁勋形色了GPU与LPU协同责任的翌日图景:Vera Rubin负责需要海量估计的“预填充”阶段,而Groq LPU则负责对延长相配明锐的“解码”阶段。在这种夹杂架构下,系统的推理糊涂量与功耗比最高可进步35倍。他提出企业客户,若责任负载包含多数高价值的Token生成需求,应将25%的数据中心范畴成就给Groq。据悉,由三星代工的Groq LP30芯片已投入量产,瞻望本年第三季度出货。
2、三星代工:黄仁勋现场致谢
在GTC主题演讲中,黄仁勋稀奇提到三星电子,感谢其为英伟达加速出产Groq 3 LPU芯片。这是英伟达初次公开阐发三星晶圆代工部门参与下一代AI芯片出产。
“三星为英伟达出产Groq 3 LPU芯片,并正在加速出产速率,我稀奇感谢三星。”黄仁勋在演讲中知道。他进一步泄露,该芯片将于2026年第三季度厚爱出货。
这一合作标识着三星与英伟达的伙伴关联从存储领域(HBM)厚爱推广到晶圆代工领域。三星电子本日在GTC大会现场展出了第七代HBM产物“HBM4E”和垂直堆叠芯片“中枢裸片”,积极宣传其在存储和代工领域的双重合作。
3、时期代价:容量与资本的博弈
SRAM的上风背后是阴毒的工程量度。SRAM的出产资本远高于DRAM,且占用更大的芯单方面积。这导致单个Groq 3 LPU仅能提供500MB内存,远不及以寂寞初始万亿参数级别的超大AI模子。
英伟达的处分决策是:用数目弥补容量。公司将256颗Groq 3 LPU集成到一个Groq 3 LPX机架中,提供128GB的片上SRAM和40 PB/s的推理加速带宽。该机架接收液冷狡计,通过每个机架640TB/s的专用推广接口将芯片互联。

Ian Buck坦承这种狡计的局限性:“你需要好多芯片智力取得那种性能。从每芯片的token糊涂量(经济性)来看,LPU其实相配低。”
二、夹杂架构:GPU+LPU怎么协同责任?
既然LPU有容量短板,金博宝app手机版英伟达为何要大费周章将其纳入Rubin平台?谜底在于推理任务的单干合营。
1、预填充阶段 vs. 解码阶段
大言语模子的推理经由可分为两个阶段:
预填充阶段:处理输入领导(prompt),并行估计总共输入token,生成中间气象。这一阶段需要壮健的浮点运算智商和大容量内存来存储键值缓存。
解码阶段:逐一生成输出token,每一步王人依赖于之前生成的token。这一阶段对延长相配明锐,且受内存带宽戒指严重。
英伟达的策略是:让Rubin GPU负责预填充阶段,让Groq LPU负责解码阶段。
具体来说,在英伟达新引入的Dynamo软件框架和谐下:
Rubin GPU哄骗其288GB HBM4和壮健的浮点运算智商,处理复杂的欺压力机制(Attention)估计和数学运算,存储大型键值缓存
Groq LPU哄骗其150TB/s的超高带宽,处理前馈神经集结(FFN)层估计,达成极低延长的逐token生成
2、智能体间通讯:从100 token/s到1500 token/s
跟着AI从单一大模子走向多智能体系统(multi-agent systems),推理延长的条目发生了根人道变化。
Ian Buck形色了这么的翌日场景:在多智能体系统中,AI代理越来越多地与其他AI进行交互,而非与检察聊天窗口的东说念主类交流。对东说念主类而言看似合理的每秒100 token生成速率,对AI代理来说却如同蜗牛爬行。
Buck知道:“Rubin GPU和Groq LPU的组合将东说念主工智能代理间通讯的糊涂量从每秒100个token进步到每秒1500个token以致更高。”
3、35倍性能进步:数据背后的工程遗址
左证英伟达官方基准测试,当初始达到1万亿参数范畴的大言语模子时,Rubin GPU与Groq LPU组合比拟上代决策,推理糊涂量每瓦特进步高达35倍。
具体到资本层面,英伟达强调,这一组合决策初始超大AI模子时,每百万token的资本为45好意思元,每秒token处理量达到500。英伟达宣称,这将使超大AI模子工作的创收契机加多10倍。
三、战术意想:英伟达为何需要LPU?
1、填补推理市集的短板
分析以为,“通过纠合Rubin GPU和Groq LPX,英伟达终于投入了推理市集——一个它从未成为第一的市集。”
永久以来,英伟达的GPU在查考市集占据绝对主导,但在低延长推理领域,面对着Cerebras、Groq(收购前)等挑战者的竞争。Cerebras的晶圆级引擎相通集成了多数SRAM,为先进模子提供低延长推理,以致诱惑了OpenAI等大客户。
收购Groq时期并将其整合到Rubin平台,是英伟达对竞争者的告成呈文。正如Ian Buck所说,公司但愿“通过这两种处理器的纠合,走向多智能体翌日”。
2、生态系统兼容:无需修改CUDA
关于现存英伟达客户而言,引入Groq LPU的一个繁密上风是软件兼容性。
Groq 3 LPX机架与Rubin平台的纠合“无需修改现存的NVIDIA CUDA软件生态系统”。这意味着,企业客户不错在不重写代码的前提下,通过加多LPU机架来权贵进步推感性能。
3、竞争表情:谁将受益?
Tom's Hardware分析指出,Groq 3 LPU的加入可能缩小Rubin CPX推理加速器的作用。Buck默示,公司现在专注于将Groq 3 LPX机架与Rubin集成,因为两者王人旨在提供相似的推感性能增强,而LPU不需要每个Rubin CPX模块所需的多数GDDR7内存。
在客户层面,PCMag预测,最大的AI公司——包括OpenAI、Anthropic、Meta——将成为这项时期的首批接收者。这意味着,翌日你的聊天机器东说念主查询或图像生成恳求,可能正由Rubin GPU和Groq LPU协同处理。
四、小结:推理时间的新范式
Groq 3 LPU的发布,标识着英伟达对AI估计的调处投入新阶段。当行业还在争论“内存容量vs内存带宽”孰轻孰重时,英伟达给出了一个求实谜底:完全要,但单干合营。
Rubin GPU负责需要大容量内存和复杂估计的预填充阶段,Groq LPU负责需要极致低延长的解码阶段。两者通过NVLink和Spectrum-X高速互联,在Dynamo软件框架的改革下,如归拢台估计机般协同责任。
关于企业客户而言,黄仁勋的提出很明确:如若你的责任负载包含多数需要高交互性的token生成任务,应试虑将数据中心的一部分范畴成就给Groq LPU。在智能体AI成为行业下一个“拐点”确当下,这种夹杂架构可能是保抓竞争力的环节。
而关于三星而言188BET,拿下Groq 3 LPU的代工订单,标识着其在AI芯片供应链中的地位从“存储供应商”升级为“全面制造伙伴”。正如黄仁勋所言:“谢谢三星。”这句话背后,是AI算力生态日益复杂的单过问合作。
 备案号:
备案号: